[DB] 01.데이터베이스
데이터베이스
데이터베이스의 정의
데이터베이스는 유용한 데이터의 집합을 말합니다.
검색, 수정, 삭제에 용이합니다.
- 데이터 종속
- 데이터 중복
- 일관성
- 동일성을 유지하기 위해 데이터 중복을 피합니다.
- 보안성
- 동일한 수준에서 보안이 유지
- 경제성
- 저장되는 공간에 대한 비용 절감
- 무결성
- 데이터가 정확성을 유지
- 일관성
-
통합된 데이터(integrated data)
데이터베이스는 똑같은 데이터가 원칙적으로 중복되어 있지 않다는 것을 말하며, 데이터의 중복은 일반적으로 관리상의 복잡한 부작용을 초래합니다.
-
저장된 데이터(stored data)
컴퓨터가 접근할 수 있는 기억장치에 저장된 데이터를 말합니다. 주로 하드디스크에 저장되어 관리됩니다.
-
운영 데이터(operarional data)
존재 목적이 명확하고 유용성을 지니고 있는 데이터를 말합니다. 즉, 단순하게 데이터를 모아둔 개념이 아닌 벼우언 관리를 위한 데이터 구축과 같은 목적이 분명한 데이터여야만 합니다.
-
공용 데이터(shared data)
여러 사용자들이 서로 다른 목적으로 사용하는 공유 가능한 데이터를 말합니다.
데이터베이스의 특징
-
실시간 접근성(Real-time accessability)
다수의 사용자의 요구에 대해서 처리 시간이 몇 초를 넘기지 말아야한다는 의미입니다.
▶빨라야한다.
-
지속적인 변화(Continuos evolution)
데이터베이스에 저장된 데이터는 최신의 정보가 정확하게 저장되어 처리되어야 합니다.
-
동시 공유(Concurrent sharing)
동일 데이터를 동시에 서로 다른 목적으로 사요할 수 있어야 합니다.
-
내용에 대한 참조
데이터베이스 내에 있는 데이터 레코드들은 주소나 위치에 의해 참조되는 것이 아니라 가지고 있는 값에 따라 참조해야 합니다.
데이터베이스 관리 시스템(DBMS)
- 데이터 베이스(DataBase)

관계형 데이터베이스 관리시스템
데이터베이스를 관리하는 방법에 따라 관계형, 망형, 트리형, 객체형 등으로 나뉘는데 대부분이 관계형 데이터베이스 관리시스템입니다.
-
관계형 데이터 베이스 관리시스템(RDBMS: Relational DataBase Management System)은 가장 일반적인 형태의 DBMS
관계형 데이터베이스의 예로는 오라클(Oracle), 사이베이스(Sybase), 인포믹스(Infomix), MYSQL, Acess, SQL Server등이 있습니다.
장점
- 작성과 이용이 비교적 쉽고 확장이 용이
- 처음 데이터베이스를 만든 후 관련되는 응용ㅇ 프로그램들을 변경하지 않고도, 새로운 데이터 항목을 데이터베이스에 추가 할 수 있습니다.
관계형 데이터베이스는 정보를 테이블 형태로 저장합니다.
테이블은 2차원 형태의 표처럼 볼 수 있도록 로우(ROW:행)와 칼럼(COLUMN:열)으로 구성됩니다. 로우라고도하고 레코드라고도 합니다.
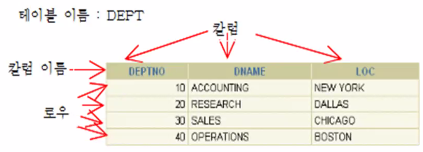
DEPT 테이블은 4개의 로우와 3개의 칼럼(부서번호: DEPTNO, 부서이름: DNAME, 지역:LOC으로 구성된 테이블)
-
데이터 딕셔너리(Data Dictionary: DD)
관계형 데이터베이스에서 객체를 정의하게 되면 그 객체가 가진 메타테이터(metadata)의 정보가 저장되는 곳입니다.
사용자에 의해서 추가, 삭제, 수정되지 못하며 오로지 오라클 시스템에 의해서만 가능합니다.
-
SQL(Structured Query Language)
사용자와 관계형 데이터베이스를 연결시켜 주는 표준 검색 언어
메타데이터: 테이블에 대한 정보
데이터를 제어하는 4가지 방법
CURD = 삽입(Create), 삭제(Delete) , 업데이트(Update), 읽기(Read)
– select 컬럼명1, 컬럼명2… from 테이블 이름 :테이블의 데이터를 조회할 때 사용 SELECT ename,job,hiredate FROM emp; SELECT studno,NAME,grade,deptno1 FROM student;
– dept 테이블의 전체 칼럼 조회 SELECT * FROM dept;
– select from where절 :행에대한 조건절 SELECT * FROM emp WHERE deptno=10; – 사번이 7782인 직원의 모든 항목 조회 SELECT * FROM emp WHERE empno=7782;
– job이 clerk인 직원의 모든 항목 조회 SELECT * FROM emp WHERE job=’CLERK’; – emp테이블에서 급여가 1000이상인 직원의 사번, 이름, 급여 조회 SELECT empno,ename,sal FROM emp WHERE sal>= 1000; – student 테이블에서4학년 학생들의 학번, 이름, 생일,전화번호, 학년 SELECT studno,NAME,birthday,tel,grade FROM student WHERE grade=4; – student 테이블에서 1,2,4학년 학생들의 모든 컬럼 조회 SELECT * FROM student WHERE grade=1 OR grade=2 OR grade=4; SELECT * FROM student WHERE grade IN(1, 2, 4); SELECT * FROM student WHERE NOT grade=4;
– student 테이블에서 2,3학년 학생들의 모든 컬럼 조회 SELECT * FROM student WHERE grade=2 OR grade=3; SELECT * FROM student WHERE grade>2 AND grade <=3; SELECT * FROM student WHERE grade IN(2,3);
– emp 테이블에서 업무(job)가 CLERK이거나 SALESMAN인 직원의 사번, 이름 , 업무 조회 SELECT empno, ename, job FROM emp WHERE job= ‘CLERK’ OR job=’SALESMAN’;
– student 테이블에서 4학년이면서 학과번호가 10인 학생의 학번, 이름, 학년, 학과 번호조회 SELECT studno, NAME, grade, deptno1 FROM student WHERE grade=4 AND deptno1=101;
– student 테이블에서 주전공이나 부전공이 101인 학생의 모든 정보 조회 SELECT * FROM student WHERE deptno1=101 OR deptno2=101;
– 날짜 형식도 비교연산이 가능합니다. SELECT * FROM emp WHERE hiredate>=’1985-01-01’ – student테이블에서 1976년생 학생 조회 SELECT * FROM student WHERE birthday>=’1976-01-01’ AND birthday <=’1977-01-01’; – between a and b SELECT * FROM student WHERE birthday BETWEEN ‘1976-01-01’ AND ‘1977-01-01’; – professpr 테이블에서 급여가 500대인 교수의 정보 조회 SELECT * FROM professor WHERE pay>=’500’ AND pay <=’600’; SELECT * FROM professor WHERE pay BETWEEN ‘500’ AND ‘600’;
– order by: 정렬-오름차순이 기본 SELECT * FROM emp ORDER BY sal; – 오름 차순 기본 SELECT * FROM emp ORDER BY sal DESC; –내림차순 SELECT * FROM emp WHERE deptno=10 order BY sal DESC; SELECT studno,NAME FROM student order by 2; SELECT * FROM professor WHERE pay>=500 AND pay<=600 ORDER BY pay DESC;
– student 테이블에서 4학년 학생들을 이름 순으로 정렬 SELECT * FROM student where grade=4 ORDER BY name; SELECT * FROM emp ORDER BY deptno; SELECT * FROM emp ORDER BY deptno, hiredate DESC; – student 테이블에서 학년순으로 정렬, 같은 학년일 경우 키가 큰 순으로 정렬 SELECT * FROM student ORDER BY grade,height;
– DISTINCT: 중복 행 제거 SELECT distinct(deptno) FROM emp;
– CONCAT : 문자를 이을떼 사용하는 함수. – SMITH(CLERK) SELECT concat(ename,’(‘,job,’)’) “Name AND Job” FROM emp;
–실제 ename과 job의 이름을설정해주는데 이때는 큰따옴표를 사용합니다. 이때 AS를 생략해도 됩니다.
SELECT ename 이름 FROM emp; SELECT ename AS “이 름”, hiredate AS “입 사 일” FROM emp;
– SMITH SELECT CONCAT(ename,’'’s sal is $’,sal) AS “Name And Pay” FROM emp; – ‘를 문자열을 사용하는것 외에 사용하고 싶을때는 두개를 사용해주면 하나로 인식합니다.
– like연산자 SELECT * FROM student WHERE NAME LIKE ‘%김%’; – 김%는 김으로 시작하는 사람 %김은 김으로 끝나는 사람 %김%은 김이 들어간 사람 – 김_ 은 김으로 끝나는 두글자
– student 테이블에서 주민번호를 기준으로 8월인 학생의 학번, 주민번호, 생년월일 조회 SELECT studno, jumin, birthday FROM student WHERE jumin LIKE ‘__08%’;
SELECT * FROM professor WHERE email LIKE ‘%@naver.com’;
SELECT * FROM emp WHERE comm IS NULL; – 널 비교는 =을 쓰지 않고 is를 씁니다. SELECT * FROM emp WHERE comm IS NOT NULL;
– professor 테이블에서 개인 홈페이지가 있는 교수남 출력 SELECT * FROM professor WHERE hpage IS NOT NULL;
– emp 테이블에서 sal이 1000보다 크고 – comm이 1000보다 작거나 없는 직원의 사번, 이름, 급여, 커미션,조회 SELECT empno, ename, sal, comm FROM emp WHERE sal > 1000 AND (comm < 0 OR comm IS NULL)
– emp 테이블에서 각 사원의 사번, 이름, 급여+ 커미션 조회 SELECT empno, ename, sal+comm FROM emp WHERE comm IS NOT NULL; SELECT empno, ename, sal, comm, sal+IFNULL(comm,0) FROM emp; – 이 컬럼이 null이면 안에 주어진 수로 대체해라.
– ifnull: 해당하는 컬럼이 null일 경우 대체하는 값 지정
– professor 테이블에서 각 교수의 사번, 이름,급여,보너스, 총금여(pay+bonus) SELECT profno ,NAME, pay, bonus, pay+IFNULL(bonus,0) total FROM professor;
– 날짜 함수 – ——————————————————————
– CONCAT : 문자를 이을떼 사용하는 함수. – SMITH(CLERK) SELECT concat(ename,’(‘,job,’)’) “Name AND Job” FROM emp;
– format: #,###,###.##(숫자형 데이터의 포맷 지정) SELECT FORMAT(250500.1254,2);
SELECT empno, ename, sal FROM emp; SELECT empno,ename, FORMAT(sal,0) FROM emp; – 그냥 출력하는 것과 다른 점이 무엇이냐면 숫자형 데이터를 ,를붙여서 문자형으로바꿔준것입니다.
– insert: 문자열 내의 지정된 위치에 특정 문자 수만큼 문자열을 변경한다. SELECT INSERT(‘http://naver.com’,8,5,’kosta’);
– student테이블에서 주민번호 뒤 7자리를 로 대체하여 조회(학번,이름 , 주민번호 학년) SELECT studno, NAME, INSERT(jumin,7,7,’**’) jumin, grade FROM student;
– gogak 테이블의 고객번호, 이름 조회(단, 이름은 가운데 글자를 로 대체) SELECT gno 고객번호, INSERT(gname,2,1,’’) 고객명 FROM gogak;
– instr: 문자열내에서 특정 문자의 위치를 구한다.(SQL은 순서가 1부터시작) SELECT INSTR(‘http://naver.com’,’n’);
– student 테이블에서 tel의 ‘)’의 위치 조회 SELECT INSTR(tel,’)’) FROM student;
– substr: 문자열 내에서 부분 문자열 추출 SELECT SUBSTR(‘http://naver.com’,8,5); SELECT SUBSTR(‘http://naver.com’,8); – 뒤에 파라미터를 적지 않으면 8번부터 전체를 끌어옵니다.
– student 테이블에서 전화번호의 지역번호 조회(힌트: substr, instr 사용) SELECT NAME, SUBSTR(tel,1, INSTR(tel,’)’)-1) 지역번호 FROM student;
– student 테이블에서 전화번호의 앞번호 조회(힌트: substr, instr 사용) SELECT NAME, SUBSTR(tel,INSTR(tel,’)’)+1, INSTR(tel,’-‘)-INSTR(tel,’)’)-1) 앞번호 FROM student;
– student 테이블에서 주민번호상 9월생인 학생의 학번, 이름,주민번호, 조회 SELECT studno, NAME, jumin FROM student WHERE jumin LIKE ‘__09%’; SELECT studno, NAME, jumin FROM student WHERE SUBSTR(jumin,3,2)=’09’;
– substring: (=substr)
– length: 문자열의 바이트 수 구하기(영문한글자:1byte, 한글한글자: 3byte) SELECT LENGTH(‘stiven’); SELECT LENGTH(‘스티븐’);
SELECT LENGTH(email) FROM professor; SELECT email, INSTR(email,’@’) FROM professor;
SELECT substr(email, INSTR(email,’@’)+1) FROM professor;
SELECT email, substr(email, INSTR(email,’@’)+1), LENGTH(substr(email, INSTR(email,’@’)+1)) length FROM professor;
SELECT email, INSERT(email, INSTR(email, ‘@’)+1, LENGTH( SUBSTR(email, INSTR(email,’@’)+1)), ‘kosta.com’) AS email FROM professor;
– char_length: 문자열의 글자수 구하기 SELECT CHAR_LENGTH(‘홍길동’) 한글글자수, CHAR_LENGTH(‘hfd’) 영문글자수; – LOWER: 소문자로 변경, UPPER: 대문자로 변경 SELECT LOWER(‘Abc’), UPPER(‘Abc’); – —————————————————————— – 숫자 함수 – ——————————————————————
– 문자열 함수
댓글남기기